
Если Вы следите за сферой футбольной аналитики, то, конечно же, знаете о компании Statsbomb. Если же нет, то Statsbomb — компания, основанная Тэдом Кнатсоном, который сперва работал в Пиннакле, а затем стал главой аналитических отделов в Мидтъюлланде и Брентфорде. С помощью него и команды из нескольких человек эти клубы в середине 10-ых сделали большой акцент на использовании футбольных данных в своей работе (почитать про Брентфорд можно здесь, а про кейс Мидтъюлланда — здесь). Примерно в то же время и была основана Statsbomb, специалзирующаяся сначала на консультировании по аналитике и тактике, а теперь уже ставшая и провайдером данных. Помимо этого, компания выпускала (и выпускает до сих пор) большое количество аналитических статей, которые во многом задают тренды в футбольной аналитике.
1 июня Тэд анонсировал проведение первой конференции на Стэмфорд Бридж в октябре, и это был отличный шанс узнать о самых актуальных исследованиях, а также пообщаться напрямую как с аналитиками ведущих европейских клубов, так и с энтузиастами из Твиттер-коммьюнити.
Расписание конференции было очень многообещающим и давало возможность выбрать послушать доклады разных людей из мира футбола. По сути, было 2 секции — секция для функционеров / тренеров / медиа и секция для аналитических гиков.
Попасть во вторую секцию мог любой желающий — нужно лишь было до 21 августа отправить свою аналитическую идею с объяснением и затем реализовать её, используя данные одного или двух сезонов 17/18 или 18/19 топ-5 лиг. (Отличный пример идеи — недавняя статья Даниэля Жолковского, выложенная в блоге Дивергенция футбольного поля)

Выбор докладов был настолько большой, что даже до начала конференции я сомневался между некоторыми докладами. Немного повезло: на первом докладе я случайно сел рядом с Ианом Грэхамом (главный аналитик Ливерпуля, на русском можно прочитать о нем здесь, на английском — здесь) и решил, что мой выбор будет совпадать с выбором соседа.
Перед первым докладом приветственное слово сказал сам Тед; вкратце рассказал о компании, показал текущие разработки / успехи и обозначил цели на ближайший год. Из интересного: он показал платформу Statsbomb IQ, которая является большим BI-tool’ом с всевозможными визуализациями и соответствующими типами анализа. Понять, что именно включает в себя этот тул, можно из статей аналитиков на сайте компании, по сути — это грамотно собранные наработки аналитиков / дизайнеров визуализации в один удобный интерфейс. Во время конференции, кстати, можно было подойти к сотрудниками Статсбомба и попользоваться программмой. Конечно же, эта конференция задумывалась не только как некий «академический» сбор вовлечённых и интересующихся людей, а в том числе и как платформа для продажи продукта самой компании. Но это абсолютно нормально.
Теперь совсем вкратце практически о каждом из докладов. Я не буду вдаваться в технические детали каждого из них, перечислю только основные выводы и предположения, которые я успел записать и понять в принципе. Все доклады были записаны на видео и будут выложены в скором времени на канал Statsbomb’a, кроме докладов Адриена Тараскона из ПСЖ и Воссе де Боде из Аякса (пока неясно, поделятся ли ими с участниками конференции).
1. Tom Decroos — Is our model learning what we think it is learning?
Том с коллегами из университета Лёвена создал метрику VAEP (Valuing Actions by Estimating Probabilities), которая покрывает не только какое-то одно конкретное действие (как это делают xG, xA и тп), а несколько (как например, xGChain, xGAdded, xT, Attacking Contributions). Метрика является классификатором того, будет ли забит / пропущен гол в течение следующих 10 действий и использует три типа переменных (простые — тип действия, результат…; сложные — расстояние до ворот, время между действиями…; контекстные — разница в счёте) для оценки.
Выводы:
- Не использовать ROC-AUC кривую как оценку результата, вместо использовать Normalized Brier Score
- Generalized Linear Regression подходит лучше для интерпретации и показывает значение итоговой метрики, слабо отличающееся от алгоритмов бустинга (xGBoost)
- Сокращение переменных до 10 слабо ухудшает качество классификатора и сильно сокращает скорость вычислений
Помимо этого, Том рассказал о новом формате SPADL, который позволяет стандартизировать данные из источников (Wyscout, Opta, Statsbomb) и приводить их из вида словарей-json в вид табличек. Это довольно интересно, тем более, что Ливерпуль озадачивался в прошлом сезоне этой проблемой. Для интересующихся: ссылка на код и библиотеку Python c реализацией формата,
2. Robert Hickman — Considering defensive risk in Exptected Threat models.
Ожидаемое расширение идеи Каруна Сингха: внедрение защитных характеристик в модель ожидаемых угроз. Честно говоря, я сам сейчас разрабатываю схожую модель, и моя мысли по этому поводу совпдают с идеей Роберта.
Проблема текущей модели xT заключается в том, что она:
- Не «наказывает» игроков за потери мяча, и соответственно, поощеряет более спекулятивные пасы. Пример: карты пасов Шелви и Крооса, где видно, что Кроос больше «разгоняет» владение по всему полю.

- Не учитывает пасы / владение глубоко в защите, которое может привести к потере мяча и пропущенному голу. Поэтому в уравнение добавляется отрицательная компонента, отражающая риск от перемещения мяча назад.
- Не учитывает возможность удара по воротам вместе паса (по идее, xG удара — первая компонента в цепи Маркова, но ударом может быть не обязательно только последнее действие в атаке.
Учитывая три данных фактора, Роберт составил свою модель по топ-5 лигам и получил следующие результаты:
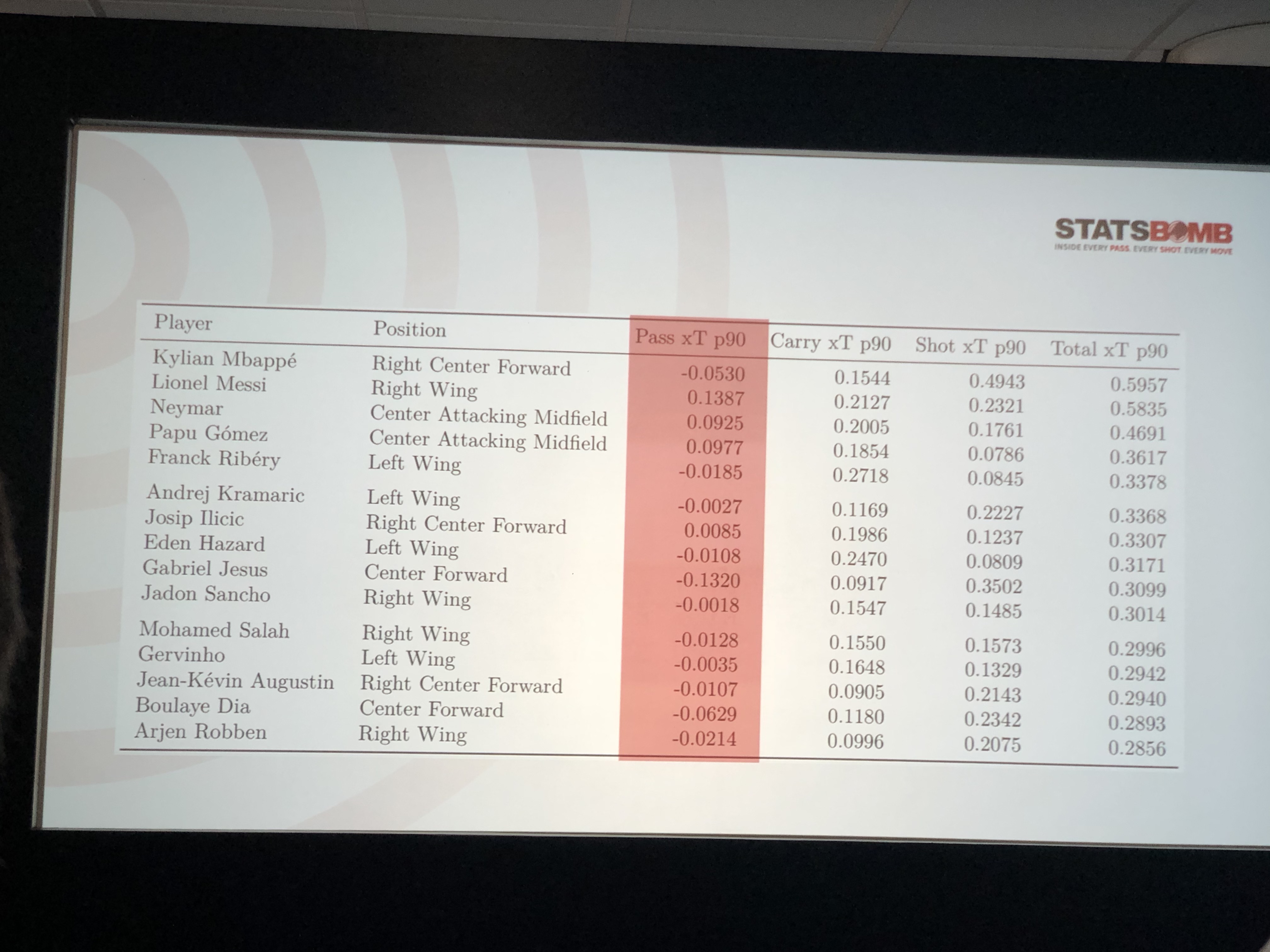
3. Javi Fernandez — Finding the free man: a contextual approach for identifying spaces that matter
Как мне показалось, глава отдела спортивной аналитики Барселоны не сказал ничего радикально нового в своем докладе и повторил презентацию, показанную на Sloan этого года.
В принципе, Expected Possession Value была довольно-таки революционной метрикой в этом году, и было бы банально сложно сделать что-то качественно новое за полгода, учитывая уровень занятости Хавьера и его команды.
Интереснее было услышать его мнение по некоторым аспектам из ответов на вопросы:
- В футболе тяжело предсказывать ходы наперёд ввиду большой динамичности игры. Контрпример динамичной игры — шахматы, ведь это первый спорт, в котором когда ходы можно было просчитать по сути гигантским оптимизированным перебором и обеспечить победу компьютера над человеком. Неясно, как моделировать индивидуальные особенности игроков, поэтому очень важна коммуникация аналитиков с тренерами касаемо краткосрочных решений во время игры.
- Ставшая классической проблема коммуникации аналитиков и тренеров: важно внедрить культуру принятия данных, ведь данные позволяют понять игру лучше. В то же время, сложно донести конкретно и ясно информацию до тренеров.
- Например, в случае с EPV идеально было бы подтверждать метрику с видео (что, в принципе, уже сделано), но возникает другая проблема — качество трекинговых данных. Очень много времени и усилий уходит на их предобработку / чистку.
- Проблемы перевода терминологии с языка клуба на английский и наоборот дополнительно усложняют процесс коммуникации.
4. Ryan Beal, et al — Valuing player influence within teams
Райан попытался с помощью теории графов оценивать степень вовлечения / важности игрока в командную игру. Имея данные по АПЛ за прошлый сезон, он анализировал графы владения мячом, выделял различные события в матчах, оценивал их веса во вклад в итоговый результат игры и на основе этого приходил к самым “командным” игрокам. Затем он анализировал самые “подходящие” друг другу пары игроков.
- Неудивительно, что и в одиночных рейтингах, и в рейтингах пар высшие места занимали игроки Манчестер Сити (Фернандиньо, Сильва, Лапорт. Уокер), так как более длинные владения зачастую приводили к голу и, соответственно, улучшали результат.
- Проблема в вычислительной способности данной модели: теоретически она позволяет подобрать целые команды игроков, но неясно, как учитывать неравное количество времени, проведённое на поле, а также травмы.
5. Thom Laurence — Some things aren’t shots: comparative approaches to valuing football actions
Презентацию от текущего CTO Statsbomb’а (и бывшего аналитика пражской Славии) было интереснее всего слушать, так как во-первых, в ней были описаны совершенно новые технические вещи, а во-вторых, будучи хорошим рассказчиком, Том часто разбавлял доклад разными забавностями и не давал скучать аудитории. После релиза метрики, разработанной в Барселоне, Статсбомб начал думать, как её можно улучшить, ведь EPV не идеален: он во многом акцентирован на владении, не включает себя вторые мячи (second balls), риск потери мяча в защите, перехваты, а также розыгрыш мяча с центра поля, когда мяч сразу выносится в аут в сторону финальной трети (подробный разбор такого розыгрыша можно прочитать вот здесь)
Абсолютно логичное и закономерное техническое решение — использовать Reinforcement Learning. Вкратце — это область машинного обучения, в которой ИИ обучается не только на доступных исторических данных (как в обычном обучении с учителем), а взаимодействуя с окружающей средой. Придумать такие алгоритмы сложно, так как что многие передовые алгоритмы запатентованы (например, алгоритм NB от Google).
Статсбомб написал нейросеть, которая использует 8 возможных типов действий на поле и в итоге определяет вероятности того или иного исхода матча со временем. Вот пример графика одной из игр.
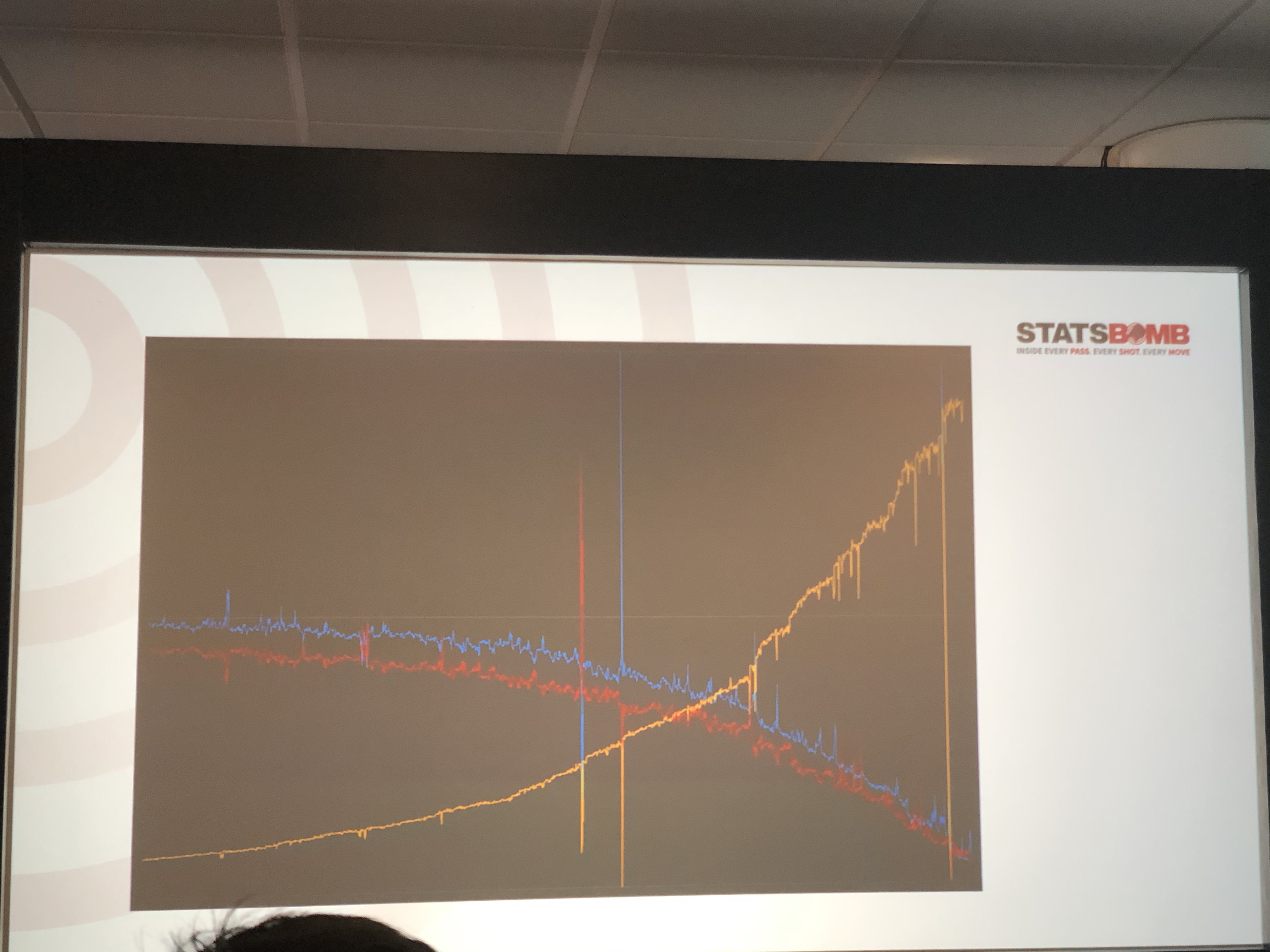
Синяя линия отображает вероятность победы, красная — поражения, жёлтая — ничьи. Видно, что на графике очень много пиков — это удары. Также видно домашнее преимущество (и это отдельный вопрос — как замоделировать и верно определить то, что его даёт), увеличение вероятности ничьи к концу матча (что логично), а также странные колебания кривых к концу матча. При более точной настройки нейросети эти колебания должны исчезнуть, но пока что ближе к концу нейросети примерно без разницы на результат, и она задаёт его вероятности каким-то случайным шумом.
Также Том отдельно выделил базовые вещи, на которые стоит и нужно обратить внимание при моделировании любой модели в принципе:
- Нужно теститровать модель (и не только на экстремальных наблюдениях по типу Месси), а также проверять её на целесообразность в принципе.
- Многие модели сильнее оценивают атакующий вклад, нежели защитный; при моделировании стоит думать об устрашении этого смещения.
- Внедрение более детальных данных позволить делать модели точнее, но неясно, когда это будет.
Эту презентацию я особенно хочу пересмотреть, так как по моему мнению, это самое актуальное, что есть в открытом доступе сейчас в индустрии. Но следующие две я хочу посмотреть ещё и потому, что просто не успел записать и понять то, что было рассказано :)
6. David Perdomo, et al — How to break a set defence
Дэвид и его коллеги из компании Twenty3 выступали первыми и задались вопросом, какие атакующие события показывают атаку против «сложившейся» защиты и что на это влияет. Они выделили 4 фактора:
Длительность атаки (максимум 20 секунд)
Пинболл (здесь надо ещё раз посмотреть презентацию, чтобы вспомнить определение)
Позиция центральных защитников (если они располагаются на высоте 43,75 метра)
Скорость атаки: (не менее 4.375 метра в секунду)
Когда владение мячом выполняет все 4 условия, владению присваивается позитивный лейбл (TRUE), иначе — негативный (FALSE). Затем каждая группа владений делится ещё на некоторое количество кластеров и анализируется подробнее.
7. Michael Caley: Passing, press-breaking and footedness: Exploring the Statsbomb’s new data
Имя Майкла должно быть знакомо любителям футбольной аналитики, он одним из первых создал свою модель xG и внёс большой вклад в её популяризацию. На самом деле Caley — его ненастоящая фамилия, настоящая фамилия Майкла — Haxby, но так как уже есть один известный Майкл Хаксби, он довольно долго искал себе новую фамилию :)
В своей презентации он делал акцент на метриках прессинга:
PPDA (Colin Trainor), Moves Broken (Michael Caley), CB Zone Passing (Paul Riley), Modeled Pass Percentage Against (Will Gurpinar-Morgan), High Turnovers Won (Anfield Index / Gaps Tandon)
Основываясь на этих метриках, Майкл выделил следующие группы команд для более подробного анализа( здесь нужно точно пересматривать, так как презентация шла час и учитывая акцент и скорость Майкла, пересматривать придётся не раз):
- Команды с высоким прессингом: Эйбар, Манчестер Сити
- Команды с эффективным прессингом: РБ Лейпциг, Бавария
- Команды с неэффективным прессингом: Торино, Барселона, ПСЖ
- Команды, которые в течение 2 последних сезонов претерпели тактические изменения: Челси, Тоттенхэм
- Команды со странными цифрами: Реал Мадрид, Реал Сосьедад, Бёрнли, Борнмут, Лацио, Марсель
Затем он показывал много скаттерплотов разных метрик друг против друга и пытался объяснить тенденции, но я просто не успевал записать.
Очень понравился последний слайд одного из докладывающих касаемо его модели:

Понятно, что конференция была не только площадкой для презентации результатов, но также и местом, где можно было получить конструктивную критику касаемо своих исследований.
После всех презентаций было дано 2 часа на общение участников между собой, где удалось пообщаться со многими интересными людьми. Например, удалось немного поговорить с Ианом Грэхамом про его работу в Ливерпуле. Мы обсуждали вопрос донесения информации до тренеров и он привел простой пример: в своей работе Клопп очень сильно обращает внимание на общий пробег команды. В один момент сезона его команда лидировала по этому показателю по лиге, но когда через некоторое время их пробег упал, Клопп обратил на это внимание и захотел перестроить тренировочный процесс, в то время как остальные цифры были в порядке. Аналитикам Ливерпуля пришлось объяснять тренеру, что всё в порядке и что не только эта цифра является в целом определяющей.
Также удалось поговорить с человеком, который создает обучающие программы для тренеров в английской федерации футбола, и она сказала, что уже начиная с категории B, они постепенно внедряют в программу обучения тренеров базовые элементы работы с данными. Сейчас я учусь в Германии на первую тренерскую категорию C, и здесь мне сказали, что работа с данными начинается только после категории А.
В целом, поездка в Англию оправдала все ожидания и затраты. Судя по всему, в следующем году Statsbomb организует ешё одну, и я уверен, что туда стоит ехать, ведь не так часто удаётся встретить столько людей из индустрии в одном месте и получить столько информации. К тому же, Статсбомб дал всем участником данные по всему сезону АПЛ 2017/18, что очень приятно.
