«Вы опросили всего N = 1000 респондентов. Как эти результаты могут быть репрезентативными для всей страны с миллионным населением?»
Если вы задавались тем же вопросом, вы не одиноки. Мы часто получаем эти вопросы от читателей и клиентов, которые боятся доверять опросам, которые опрашивают лишь небольшую часть людей, чтобы получить информацию для всей целевой аудитории.
Итак, достаточен ли размер выборки N = 1000?
Да и нет.
Давайте сначала разберемся с «да»
Распространенное заблуждение, когда дело доходит до опросов, заключается в том, что для получения надежных результатов необходимо опросить действительно большую часть населения. Это просто неправда.
Размер выборки N=1000 может обеспечить достаточно точное представление генеральной совокупности с погрешностью примерно +/- 3%, если выборка выбрана случайным образом, является репрезентативной для генеральной совокупности и если опрос хорошо спланирован.
Важным фактором, о котором следует учитывать, является запас или ошибка. Итак, что же такое МО?
Ну, часто по-человечески невозможно опросить каждого человека из целевой аудитории (например, всю страну или всех курильщиков). Вы сможете исследовать только часть из них. Погрешность показывает, насколько далеки от «истинного» значения совокупности результаты вашего опроса. Так, например, если результаты вашего опроса показывают, что «30% сингапурцев любят желтый цвет при МО +/- 5%», это означает, что «истинное» значение фактического населения может находиться где-то между 25%-35%. . В идеале вы хотели бы, чтобы ваша погрешность была низкой, чтобы вы могли получить точную оценку.
Теперь погрешность во многом зависит от размера выборки вашего опроса, и они имеют обратную зависимость. Чем больше размер выборки, тем меньше погрешность. ±3% обычно является приемлемым уровнем погрешности для обследований, ориентированных на население в целом.
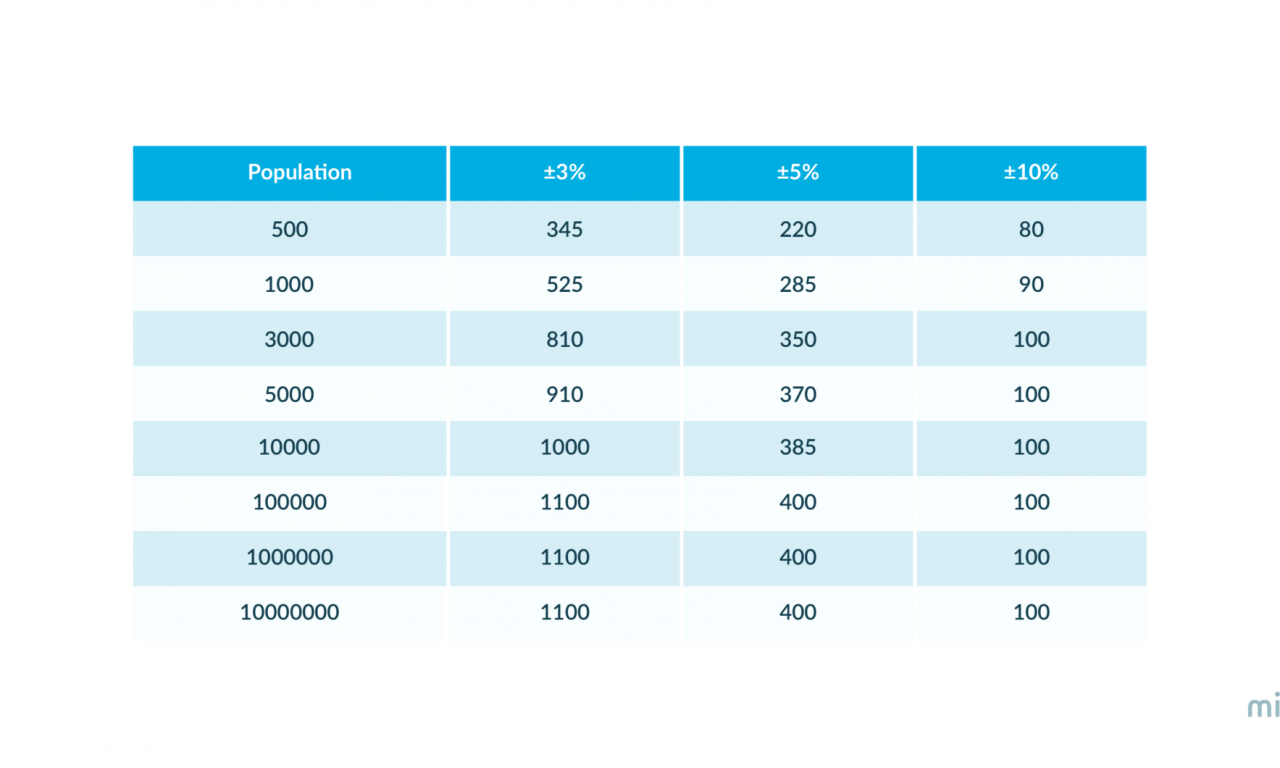
В таблице ниже показано, что если вы стремитесь к MoE ±3%, вам нужно только N = 345 образцов, если ваша целевая совокупность составляет N = 500. Интересно, что размер выборки N = 1000 дает вам тот же уровень точности для все размеры популяции выше N = 10 000. Это означает, что если вы хотите получить результаты опроса, отражающие мнения, например, 6 миллионов сингапурцев, вам подойдет размер выборки N = 1000.

В этой таблице перечислены размеры выборки, к которым вам следует стремиться, в зависимости от размера целевой совокупности и желаемой погрешности.
Теперь переходим к той части, где N = 1000 может оказаться недостаточно хорошим.
Допустим, вы опрашиваете группу из N = 1000 респондентов, чтобы сделать выводы об общей популяции. Чтобы сделать точные выводы, важно обеспечить случайный отбор респондентов и репрезентативность выборки по ключевым демографическим критериям. Часто бывает трудно контролировать множество демографических переменных, поэтому обычно контролируют те немногие, которые могут привести к наибольшим отклонениям в теме, по которой вы проводите опрос (например, возраст, пол, местоположение и доход семьи).
Обычно это делается с помощью метода, известного как квотная выборка. Квотная выборка – это метод невероятностной выборки, при котором план выборки создается до проведения полевых работ. Например, вы можете установить квоты, чтобы гарантировать, что ваша выборка состоит из равного распределения мужчин и женщин (N = 500 каждый вместо, например, искаженной выборки, состоящей из n = 800 женщин и N = 200 мужчин). Таким образом, вы можете гарантировать, что результаты вашего опроса точно отражают результаты целевой группы населения.
Это также зависит от контекста и цели опроса. При размере выборки n=1000 вы можете получить общее представление о мнениях или характеристиках населения, если выборка репрезентативна для населения и опрос хорошо спланирован. Однако могут потребоваться более крупные размеры выборки, если вы хотите сделать выводы с большей точностью или если ваша совокупность очень разнообразна, или если вы хотите детализировать подсегменты внутри совокупности, которые могут быть нишевыми и труднодоступными (например, меньшинства). этнические группы).
 EUROPEAN UNION
EUROPEAN UNION
